
これまでPythonの様々なライブラリの中で、urllib や requests を利用してWebページ上の情報へアクセスする方法を紹介してきました。
こちらの記事では以前のサンプルソースコードでは気をつけて実装していなかったタイムアウト処理について解説していきます。Webアクセスする場合には自分のPCの外部へアクセスすることになるため、できるだけ安全な処理を書いておいた方が良いです。さっそく使い方を確認していきましょう。
インストール
今回の記事でも requests を利用しますので、インストールが必要な場合には pip install requests などを実行してライブラリを利用できるようにしておきます。
requests get の基本的な使い方(timeout 設定あり)
これまでも何度か利用していますが、厚生労働省のオープンデータ を参考にして、pythonのプログラムからデータを取得してみます。これまでと同じようにデータにアクセスしますが、timeout のパラメータを設定することで、挙動がどのように変わるか?それにどのように対応するのか?に注目して見てみます。
サンプルソース
サンプルの実装です。
- オープンデータのURLにアクセスしています(get)。
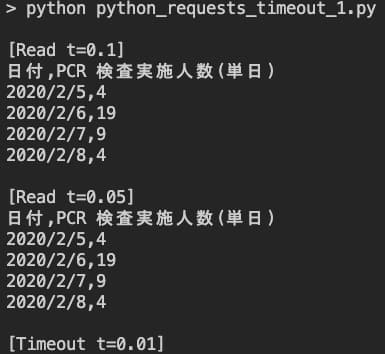
- for文を使って、timeout を設定してみます。timeout は0.1、0.05、0.01と徐々に短くしています。
- もし読み込めた場合には、これまでのようにコロナのデータを取得してprintします。
- timeout に失敗し、 requests.exceptions.Timeout の例外を検知した場合にはそちらで処理を受け取ります。
実行結果
実行した結果はこのようになりました。0.1 と 0.05 を設定した場合にはインターネット上からデータを獲得することができましたが、0.01の場合には失敗したことが分かります。
2つの Timeout を設定したサンプルソース
requests では timeout を2つ設定することができます。1つ目は接続に関するもの(connect timeout)で、2つ目はデータを読み込んで読み終わるまで(read timeout)のものです。それぞれ設定する場合にはタプルで指定します。
- 接続するタイムアウトについては0.1で固定しておきます。
- データ読み込みに関するタイムアウトについては、for文で0.1、0.5、0.01と変化させ、例外が発生するかどうかを確認しました。
2つの timeout を設定した実行結果
実行結果はこちらになります。
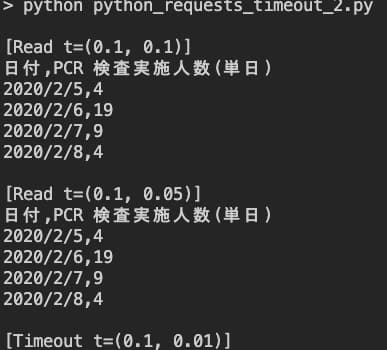
こちらの場合も、データ処理時間が短すぎる場合には例外が発生しました。
スポンサーリンク
このように適切なタイムアウト処理を設定し、例外処理することは読み込むデータによっては大切になります。例えばサーバーが内部で重い処理をする場合など、接続を確立していても読み込みに時間がかかる場合があります。うまくタイムアウト処理と例外処理を実装することで、より安全に requests を利用してデータアクセスが可能です。是非使ってみて下さい。





